Dc
Famosos
Juego De Azar
Compatibilidad Del Zodiaco
Editoriales
Biografía
Blog
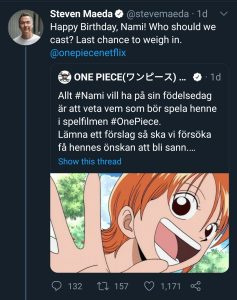
Noticias La adaptación de One Piece de Netflix tendrá un elenco diverso -Anuncio publicitario- (adsbygoogle = ventana.adsbygoogle || []).push({}); por